proc sql feedback - select句 * を展開したり、SASビューの定義をログに表示する - SAS
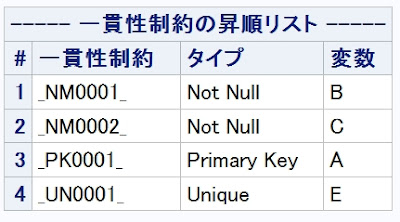
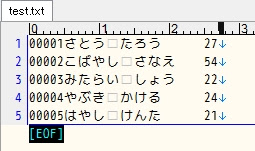
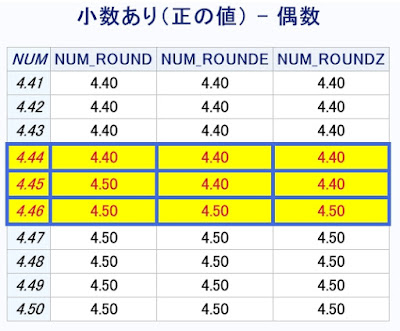
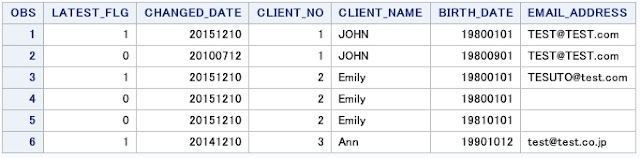
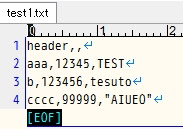
proc sql の feedback オプションについてのご紹介です。 テストコード 1 - proc sql feedback options msglevel=i ; /* テストデータ */ data TEST ; STR = "TEST" ; do I=1 to 1E5 ; R = ranuni(1) ; G = mod(I, 10) ; output ; end ; run ; %let TABLE_NAME = TEST ; proc sql feedback ; create table TEST1 as select * from &TABLE_NAME. /* コメント */ ; quit ; NOTE: Statement transforms to: の後に、SELECT句の * が展開された形で、SELECT文がログに表示されます。マクロ変数も展開され、コメントは削除されます。 71 proc sql feedback ; 72 create table TEST1 as 73 select * 74 from &TABLE_NAME. /* コメント */ 75 ; NOTE: Statement transforms to: select TEST.STR, TEST.I, TEST.R, TEST.G from WORK.TEST; NOTE: テーブルWORK.TEST1(行数100000、列数4)が作成されました。 76 quit ; NOTE: PROCEDURE SQL処理(合計処理時間): 処理時間 0.03 秒 CPU時間 0.04 秒 テストコード 2 - proc sql feedback : SQLビューを表示できます。 /* テストデータ2 */ data IDX ; G = 1 ; NOTE = "...